药物-药物相互作用(Drug-Drug Interaction, DDI)与药物-靶点相互作用(Drug-Target Interaction, DTI)的准确预测对于医学临床决策支持和药物研发具有重要的指导意义和现实价值。一方面,药物分子与生物体内靶点结合的微观机制往往是联合用药产生临床毒副作用或协同疗效的前置条件;另一方面,随着图神经网络和大语言模型等先进人工智能技术的演进发展,如何在生物医学数据中精准捕捉药物-药物与药物-靶点的相互作用模式,已逐渐成为现代计算药物设计的核心范式。然而,长期以来DDI与DTI的预测任务多处于分立的发展状态,在一定程度上忽视了两者在生物学机制与算法设计上的内在联系。

2026年5月29日,生命中心/清华大学生命学院王童课题组在国际学术期刊《高级科学》(Advanced Science)上发表了题为《先进人工智能技术如何塑造药物-药物与药物-靶点相互作用建模》(How Advanced Artificial Intelligence Technologies Shape Drug–Drug and Drug–Target Interaction Modeling)的长篇综述文章,以生物学机理为起点,从人工智能算法设计的多个维度出发,系统梳理了药物相互作用领域的共性演化趋势,并结合新型的定量实验分析了当前AI模型所面临的核心瓶颈,为未来构建统一的药物相互作用通用预测模型提供了新的思路和方向。
本综述通过综合分析近年来先进的DDI与DTI人工智能预测算法,明确了两者在特征工程、模型架构以及学习范式等多个维度的演化路径。在特征工程上,DDI与DTI预测任务已从传统的单一分子结构或序列输入,向整合多模态信息的生物医学知识图谱演进;在模型架构上,图神经网络和Transformer已成为核心骨干以同时捕获局部特征与全局依赖;在学习范式上,元学习、对比学习与集成学习等先进学习范式正逐渐受到研究学者的关注。
与此同时,为了全面分析人工智能技术在药物相互作用预测领域的发展现状,本综述系统阐述了该领域需要面对的重要挑战。首先,预测模型的泛化能力应是模型设计的关键因素。文中的实验结果表明,现有人工智能模型在暖启动任务下(即训练数据与测试数据随机划分,存在生物实体重叠)表现良好;但在面对未在训练数据中出现的全新药物或新型靶点(即冷启动任务)时,多数高精度模型的预测性能出现了较为明显的下降,数据稀疏性依旧是制约模型泛化到更广阔化学空间的核心难题。
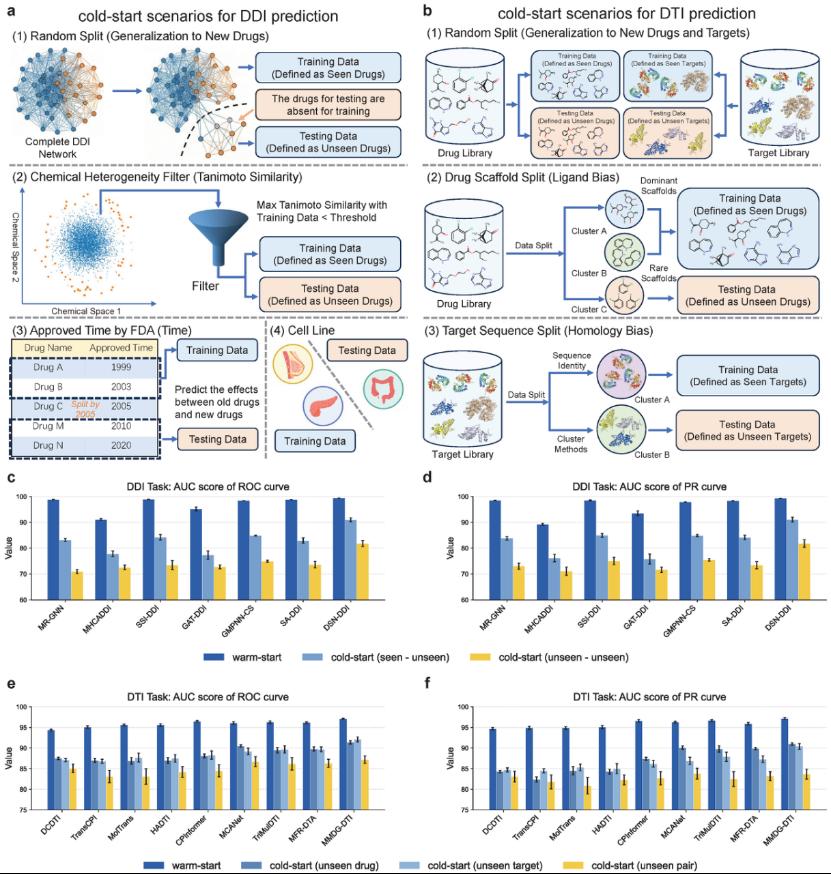
图1 冷启动场景示意图以及DDI与DTI预测任务中冷/暖启动场景模型性能对比图。a-b, DDI与DTI冷启动划分策略;c-d,DDI预测冷/暖启动性能对比;e-f,DTI预测冷/暖启动性能对比。
此外,本综述通过对各类常用公共数据集进行比对,指出当前领域内缺少统一的数据预处理规范和标准,进而导致不同研究中相同数据集的样本规模存在差异。这为准确客观地评估算法性能带来了隐性偏差。
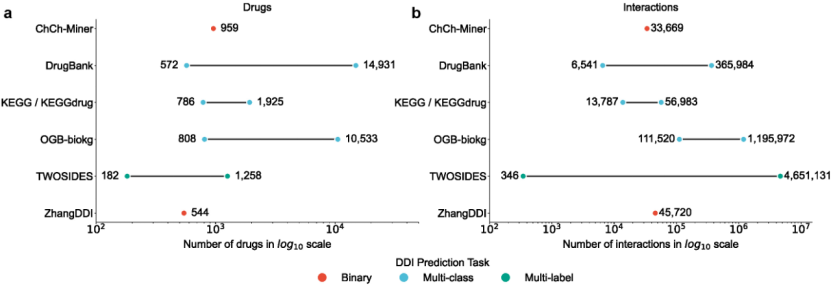
图2 DDI预测任务数据集样本规模差异。a,药物数量分布;b,药物互作对数量分布。
重要的是,本综述进一步引入了定量实验,揭示了当前DDI与DTI预测模型普遍存在的捷径学习问题。为了检验模型是否真正学习到了分子间真实的物理化学结合法则,研究团队设计了新型的“自配对伪负样本实验”。在该项实验中,研究团队首先统计了各个药物与靶点的阳性标签率,并针对每种药物和靶点分别构造<药物,药物>与<靶点,靶点>自配对伪样本,以检测只存在单方实体信息时预测模型的决策表现。实验结果显示,多种不同架构的深度学习模型表现出捷径学习倾向:模型更倾向于记住训练数据中阳性标签频率更高的药物或靶点,进而根据实体流行度给出更高的互作概率得分,而非真正提取出了可靠的分子相互作用机制。
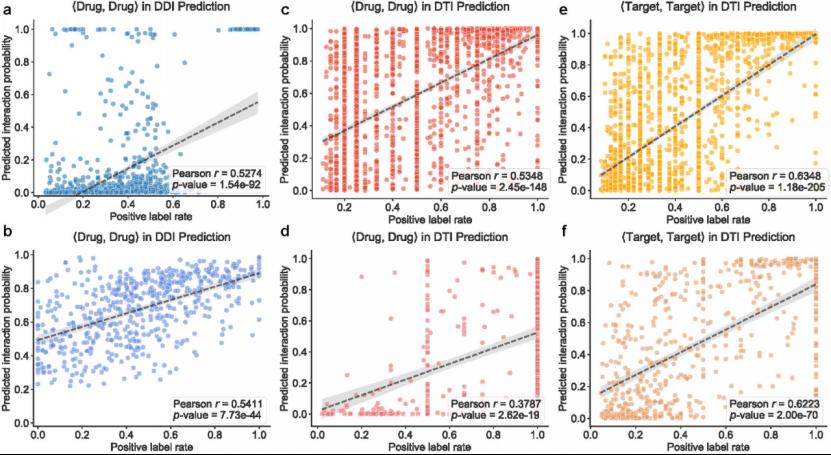
图3 捷径学习验证实验。a-f,多项不同架构的预测模型产生捷径学习倾向,模型倾向于向阳性标签频率更高的药物或靶点赋予更高的互作概率。
文章最后表明了该领域的发展方向:未来的预测架构应实现DDI与DTI任务的联合协同优化,共享统一的底层药物和蛋白质编码器,实现知识共享;需要将因果推断机制融入表征学习网络,并结合机器学习力场等物理学约束,推动模型学习真正的物理因果关系;利用前沿大语言模型从非结构化临床报告、科研论文和失败的实验报告中提取隐式关联以补全结构化数据,缓解数据局限。
生命中心/清华大学生命科学学院王童助理教授为本综述的通讯作者。清华大学生命科学学院2026级博士生孙昕为本综述第一作者。该研究工作得到了中国国家重点研发计划、清华-北大生命科学联合中心以及北京生物结构前沿研究中心等机构的经费支持。
论文链接:https://advanced.onlinelibrary.wiley.com/doi/10.1002/advs.75819


